Are you still looking into your Crystal ball for answers?


TL;DR: Using Facebook's forecasting algorithm (Prophet) to perform statistical analysis on NYSE / NASDAQ stocks to give predictions on price. The data is presented using Streamlit, a Python web application framework, for interactive data applications.
Background
Over the past year, there have been many news stories that have made the headlines notwithstanding the draconian news stream of a global pandemic, political upheavals the likes of which has never happened before and the reality that the ecosystem we inhabit is in a state of flux.
Some might agree that our futures have yet to be decided and some may even feel it is what we do in the present that will ultimately shape our future endeavours. One thing is for sure, within the scope of technology; automation and data is a present driving force that will shape and define our futures in unimaginable ways.
An area of parabolic like movement in recent times is Machine Learning (ML) and within this evolving concept is how to utilise statistical analysis to aid our everyday decision-making process and provide perspective attained from historical data points.
Reflecting over the past year there have been several stories that have caught the attention of mainstream news. One area, in particular, is the Stock Market, specifically NASDAQ, NYSE and the S&P 500 et al. It forms one facet on which the current international monetary system is built upon and anybody with a traditional yielding savings account is already exposed to these market places. Appreciating, that this is a broad stroke view but it’s fair to say that what happens every year on various stock exchanges has a direct effect on most people’s lives.
With this in mind and looking at the numerous news stories about the turbulent nature of Wall Street and how the S&P 500 is not immune to constant volatility. This got the creative juices flowing when thinking about having a perspective on stock price volatility.

Specifically, how could one cast aside the human emotions of fear and greed and how to avoid external noise or influence during times of uncertainty. Stating that previous history is not an indicator for future performance could be considered a fair and balanced approach.
However, it is now possible to give distinct and probable outcomes based on previous cyclical trends. As such, using ML and forecasting algorithms we can use historical data to help formulate a logical standpoint on how a stock's price has arrived at today’s value and based upon this where will this stock price value end up in the days, weeks, months and years ahead.
Purpose
The primary purpose of this demo/tutorial was to give a high-level overview of how anyone could use open-source software packages to assist with forecasting.
Perhaps this demo might even give useful insights on various trends that exist for particular company stocks which otherwise may not be appreciated when dealing with human emotions. When attempting to find the answers to questions such as how, when, why. Ideally, we want to separate our opinion from fact, as opinion has a tendency to cloud our judgement and our, otherwise, sound reasoning (assuming of course this sounds like you 😀), when we want to change our thought process to one that is based upon factual historical evidence.
The specific type of forecasting conducted in this project is described as being time series. Time series forecasting could be considered challenging given the vast array of methods that can be used and the associated hyper-parameters therein. Using the Prophet Library allows for relatively straight forward usage when making a univariate time series dataset.
It must be noted that the inputted data, the ML training process and the resultant output are for demo purposes only. However, after reading this tutorial I hope to inform the reader on:
- The open-source library, as developed by the boffins at Facebook, called Prophet which was been designed for automatic forecasting
- How to train the data specific to Prophet and generate forecasts
- How to build a locally hosted web application using Streamlit
- How to interpret the results using Plotly
Assumptions
Programming Skills
The reader is not expected or required to know who to read or write code and develop applications in a specific construct. The below commenting on the various code sections should at least guide the reader to follow along with the logic. Even if it does look like "double dutch". And for the record, I have nothing against The Netherlands, their beautiful language or their industrious gifts to the world 😉
If writing or reading code is not your thing or you have no interest in ever doing so and you cannot compel yourself to read any further then maybe skip to the end where the forecasted results are presented in the web application.
However, if you do find the subject matter interesting then the only ask of you is to remain open-minded about revisiting the logic in this tutorial again in the future and perhaps reuse it for the greater good.
System Specs
The baseline requirements to successfully run and execute the ML model is:
- 3 vCPU
- 10 GB RAM
Note: Given that the, above mentioned, system specification may not be readily available to everyone. In a later tutorial, I will demo how to run this application on a public cloud platform.

Tutorial Logic
The demo can be viewed from five standpoints:
-
Accessing publicly and freely consumable data in the form of Yahoo! Finance records for: Tesla, Inc.(TSLA) and Apple Inc. (APPL)
o Loading data
o Plotting data -
Forecasting a stock price with Prophet
-
Visualising data with Plotly
-
Building web applications using Streamlit
Tools
Prophet Library
“Facebook Prophet” described as being an open-source library for univariate time series forecasting. It implements what is considered an additive time series forecasting model which can support trends, seasonality and holidays.
A high-level overview on the quick start guide shows that there is a relatively low barrier for entry when it comes to utilising this particular package and as such it’s fair to assume that this was by design. Allowing for easy and automatic executions that could be used for internal company usage when forecasting sales or perhaps capacity planning.
Other libraries
In this tutorial, I choose the Python (3.8.9) based package to interface with the Prophet library. There are several other components required to successfully execute this demo application:
-
Streamlit
This is a web application framework for data applications -
yFinance
This open-source python library can be used to download and access historical data from Yahoo! Finance -
PyStan
Is an interface for Bayesian inference. Allows for high performant statistical modelling -
Plotly
Is an interactive open-sourced graphing library
All of these Python libraries were installed using Pip:
pip3 install -r requirements.txt
The Application
Python Libraries
The first component of this demo application is importing the previously downloaded libraries into a python script file. Using the below as the example:
import streamlit as st
from datetime import date
import yfinance as yf
from fbprophet import Prophet
from fbprophet.plot import plot_plotly
from plotly import graph_objs as go
Data Capture Points
We need to declare the points in time between which we want to analyse. That is, if we want to fetch all data between 1st January 2015 and today's date then using the below as an example is what could be used:
START = "2015-01-01"
TODAY = date.today().strftime("%Y-%m-%d")
Web Interface
For this demo application, a web page title was constructed along with a drop-down menu to select or choose the specific stock name. And a slider bar governing the number of years into the future we want to run the forecast on.
st.title('Stock Forecast App')
stocks = ('TSLA', 'AAPL')
selected_stock = st.selectbox('Select dataset for prediction', stocks)
n_years = st.slider('Years of prediction:', 1, 5)
period = n_years * 365
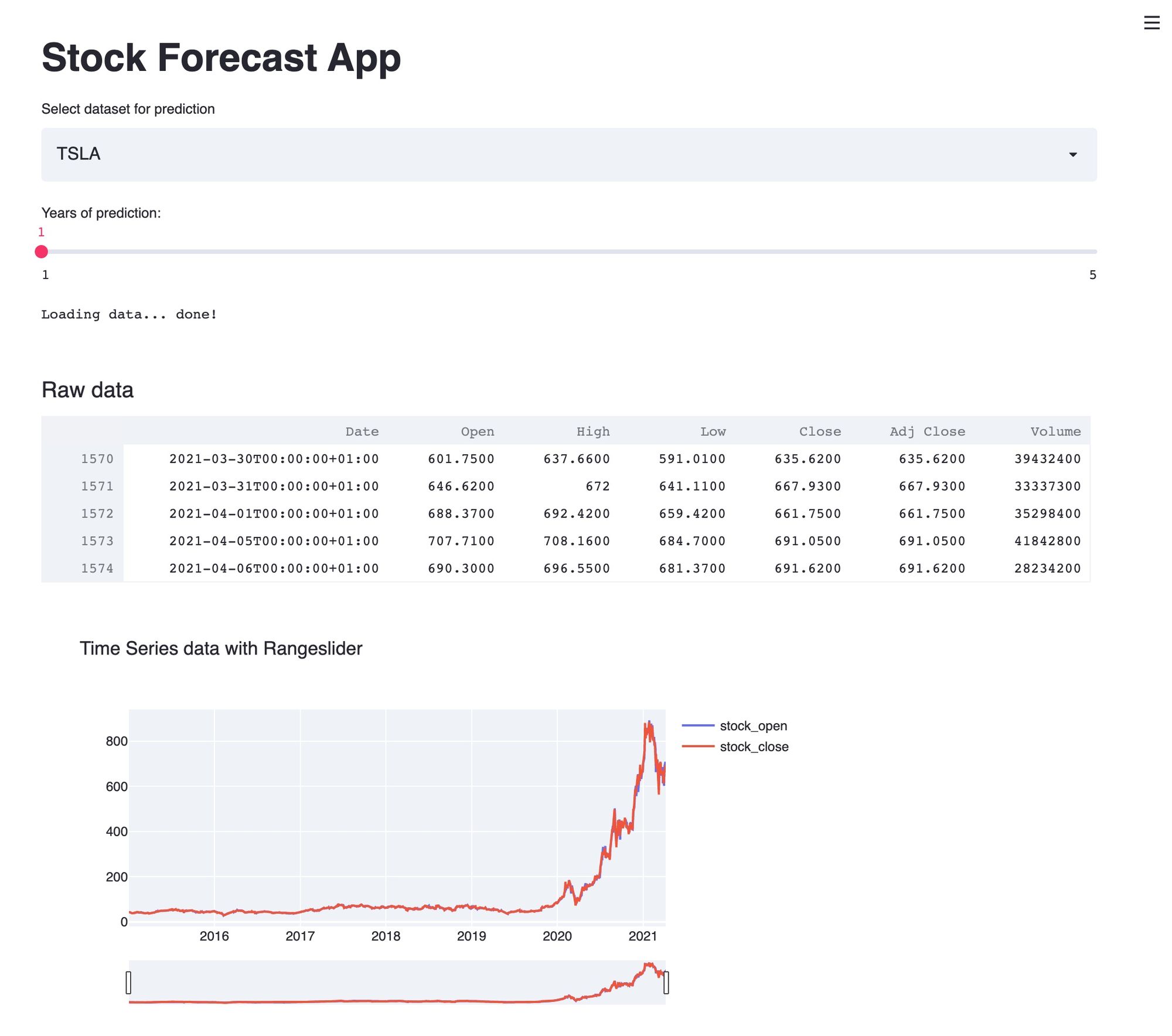
Fetching Data
A function was created to download the stock data from Yahoo! Finance. The function was created to download all data between two point of reference as per the previously declared variables: START and TODAY.
A nice feature when retrieving data from Yahoo! Finance is that it is already in a Pandas data set. Below is an example of how to retrieve and cache data for a stock ensuing that the first column of the data is the date:
@st.cache
def load_data(ticker):
data = yf.download(ticker, START, TODAY)
data.reset_index(inplace=True)
return data
data_load_state = st.text('Loading data...')
data = load_data(selected_stock)
data_load_state.text('Loading data... done!')
Writing and Plotting Data
The data table that is produced when fetching data from Yahoo! Finance is columnated in the following format:
| Date | Open | High | Low | Close | Adj Close | Volume |
Using the below Streamlit construct we can visualise this data frame via the web interface using the below logic:
st.subheader('Raw data')
st.write(data.tail())
Plotly was used to draw a graph via the function: plot_raw_data. A range slide was included to allow for more detailed view in smaller time periods. Below is the logic that governs the visualtion of the data frame and the time series graph for a stock:
def plot_raw_data():
fig = go.Figure()
fig.add_trace(go.Scatter(
x=data['Date'],
y=data['Open'],
name="stock_open"
))
fig.add_trace(go.Scatter(
x=data['Date'],
y=data['Close'],
name="stock_close"
))
fig.layout.update(
title_text='Time Series data with Rangeslider',
xaxis_rangeslider_visible=True
)
st.plotly_chart(fig)
plot_raw_data()
Executing ML Forecasting Model
Before executing the training model, Prophet expects the dataframe to be in a specific format:
Dataframe with two columns: ds and y. The ds (datestamp) column should be for a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. The y column must be numeric and represents the measurement we wish for the forecast.
In this demo:
- ds = date
- y = Close (The stock’s closing price)
Below is the example used where we fit the data into the training model using the above-mentioned formatting requirements and forecast this data by the number of years (in days) into the future.
df_train = data[['Date','Close']]
df_train = df_train.rename(columns={"Date": "ds", "Close": "y"})
m = Prophet()
m.fit(df_train)
future = m.make_future_dataframe(periods=period)
forecast = m.predict(future)
Plotting forecasted data
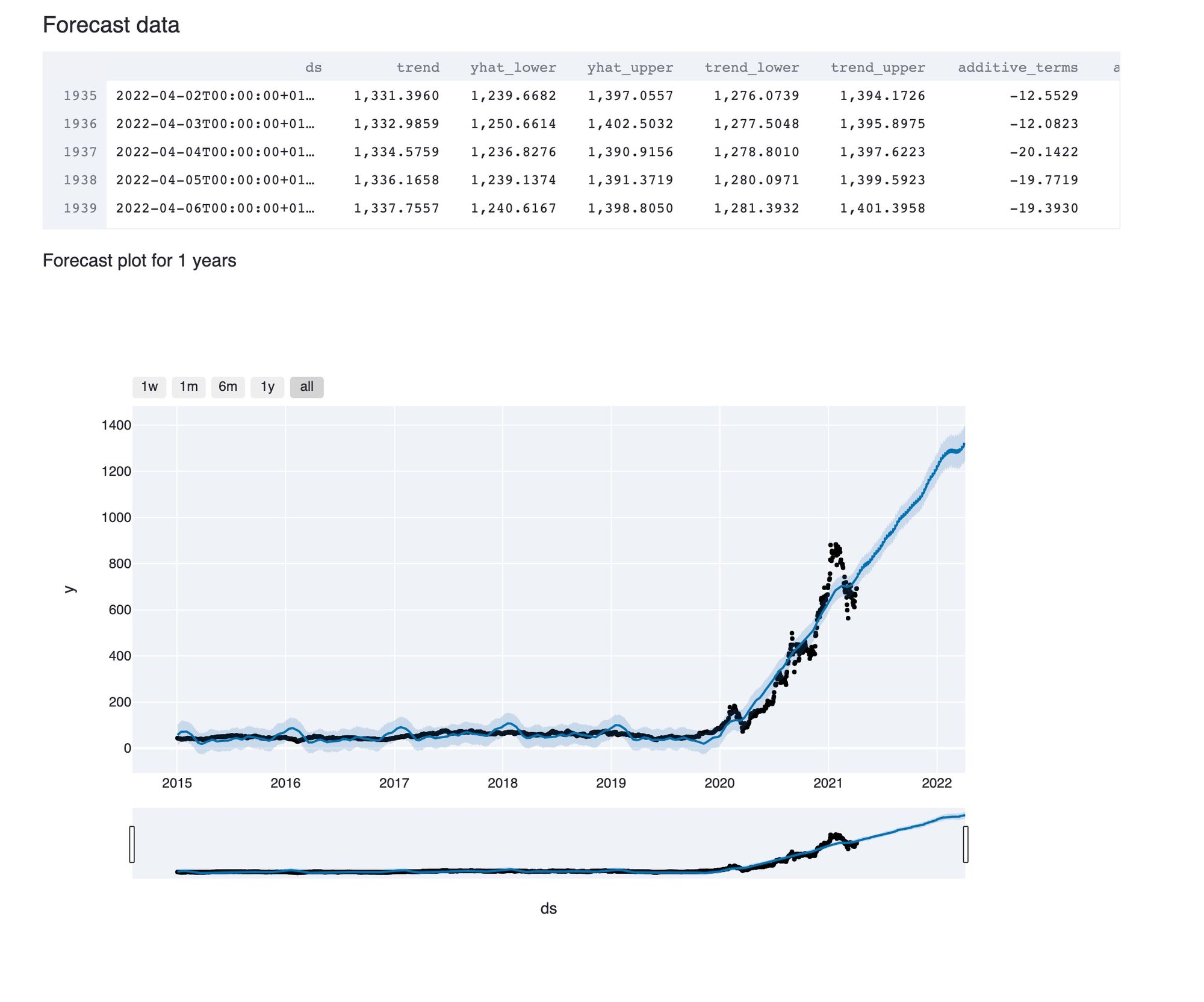
As before we will use both Streamlit and Plotly to visualise the newly modelled data. The first of the forecasted graphs is in a Plotly interface showing the projected trend line of where the forecasting price is expected to go.
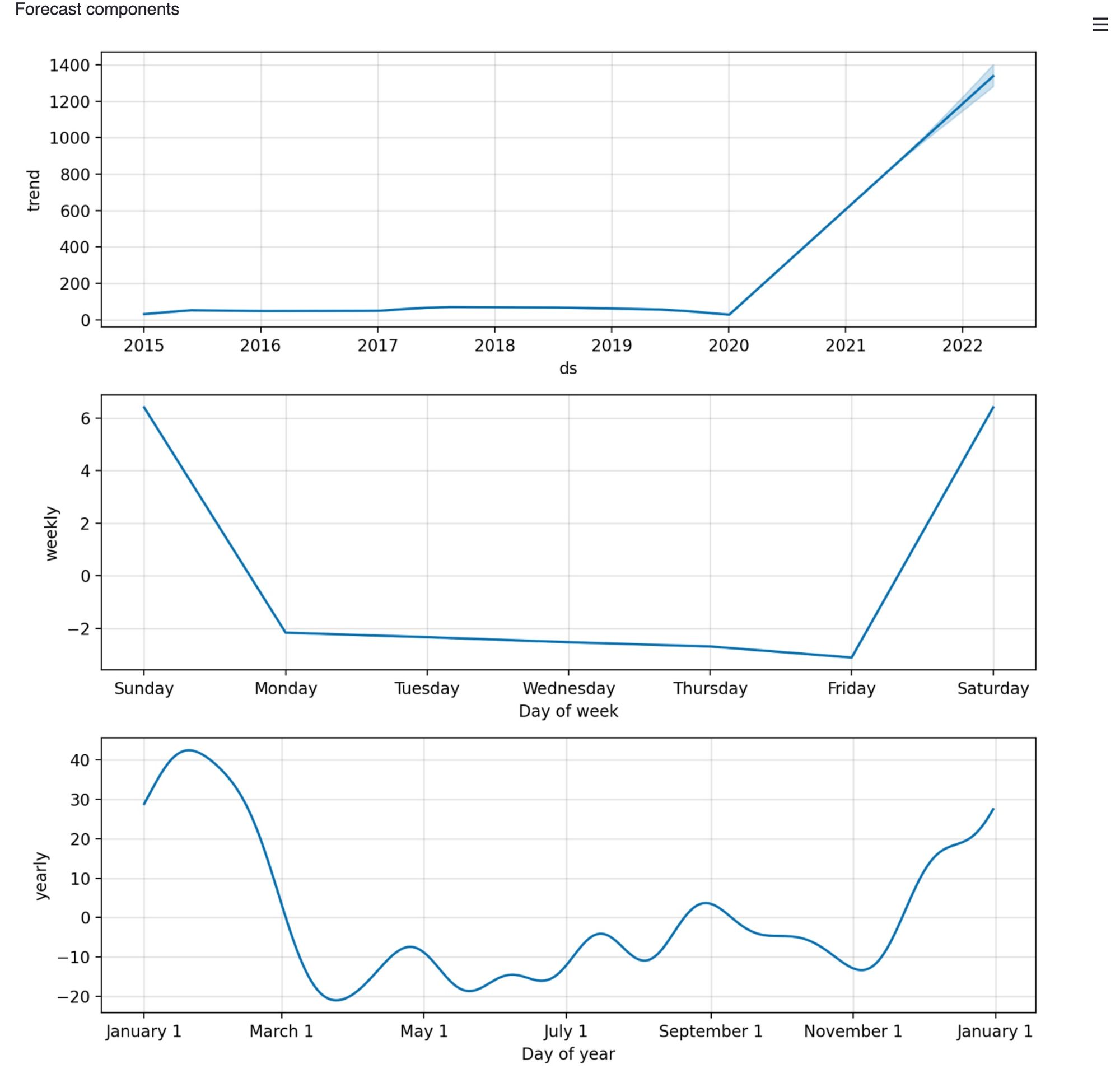
The other forecast components is a sub-interface of forecasted model data which allows us to view specific trends for a particular stock and how this value changes due to yearly and weekly adjustments.
st.subheader('Forecast data')
st.write(forecast.tail())
st.write(f'Forecast plot for {n_years} years')
fig1 = plot_plotly(m, forecast)
st.plotly_chart(fig1)
st.write("Forecast components")
fig2 = m.plot_components(forecast)
st.write(fig2)
Results
A high-level review of the resultant forecasts makes for some interesting reading, assuming you like predicting the stock market that is.
The two stocks that are demoed in this tutorial were chosen due to a broad familiarity with their names and their product offerings. As such I thought this would, in itself, stimulate some interest and perhaps enough for you, the reader, to try to edit the logic to suit your needs.
The results could very well be tuned to give more insight and accuracy when dealing with trends. Remembering, the data that was imported into this ML model was fetched from Yahoo! Finance using daily interval prices for the stocks opening and closing price.
Perhaps, using an hourly time interval rather than a daily time interval may allow for even greater insights when attempting to forecast even further into micro trends for a stock.
Further Reading
Phew, you have made it this far! Now, who wouldn't love some more reading!

In the hope that this tutorial may have stimulated some critical thinking and you if want to look a little deeper into the topic and the tools used in this.
Please see the below resources:
20 cognitive biases that screw up your decisions
Forecasting at scale; Facebook blog
Taylor SJ, Letham B. Forecasting at scale. The American Statistician. 2018 Jan 2;72(1):37-45.
Summary
The original intention of this tutorial was to demo a simple use case where using open-sourced forecasting models could be used to help formulate a logical standpoint on a specific line of query.
As such the reader will have learnt:
- About Prophet; where it originates from, what it is used for and how to use it
- Streamlit for data web application development
- Using Plotly to visualise data as graphs and/or charts
Commentary
There are no infallible ways to predict our futures given the enormous, transient, variables that exist all around us. These variables affect human emotions in different ways which eventually culminates and gives rise to some degree of bias whether this is conscious or unconscious.
Perhaps there is a time and place for both Machine Learning Algorithms and that crystal ball sitting right next to you.
Please stop by again for new tutorials, demos, projects and/or sign up for updates to have these arrive at your inbox automatically.
Until the next time; stay safe, healthy and alert to the ever-changing world around us 😎

Comments powered by Talkyard.